Nixery: Improved Layering Design
TIP: This blog post was originally published as a design document for Nixery and is not written in the same style as other blog posts.
Thanks to my colleagues at Google and various people from the Nix community for reviewing this.
Nixery: Improved Layering
Authors: tazjin@
Reviewers: so...@, en...@, pe...@
Status: Implemented
Last Updated: 2019-08-10
Introduction
This document describes a design for an improved image layering method for use in Nixery. The algorithm currently used is designed for a slightly different use-case and we can improve upon it by making use of more of the available data.
Background / Motivation
Nixery is a service that uses the Nix package manager to build container images (for runtimes such as Docker), that are served on-demand via the container registry protocols. A demo instance is available at nixery.dev.
In practice this means users can simply issue a command such as docker pull nixery.dev/shell/git and receive an image that was built ad-hoc containing a
shell environment and git.
One of the major advantages of building container images via Nix (as described
for buildLayeredImage in this blog post) is that the
content-addressable nature of container image layers can be used to provide more
efficient caching characteristics (caching based on layer content) than what is
common with Dockerfiles and other image creation methods (caching based on layer
creation method).
However, this is constrained by the maximum number of layers supported in an
image (125). A naive approach such as putting each included package (any
library, binary, etc.) in its own layer quickly runs into this limitation due to
the large number of dependencies more complex systems tend to have. In addition,
users wanting to extend images created by Nixery (e.g. via FROM nixery.dev/…)
share this layer maximum with the created image - limiting extensibility if all
layers are used up by Nixery.
In theory the layering strategy of buildLayeredImage should already provide
good caching characteristics, but in practice we are seeing many images with
significantly more packages than the number of layers configured, leading to
more frequent cache-misses than desired.
The current implementation of buildLayeredImage inspects a graph of image
dependencies and determines the total number of references (direct & indirect)
to any node in the graph. It then sorts all dependencies by this popularity
metric and puts the first n - 2 (for n being the maximum number of layers)
packages in their own layers, all remaining packages in one layer and the image
configuration in the final layer.
Design / Proposal
(Close-to) ideal layer-layout using more data
We start out by considering what a close to ideal layout of layers would look like for a simple use-case.
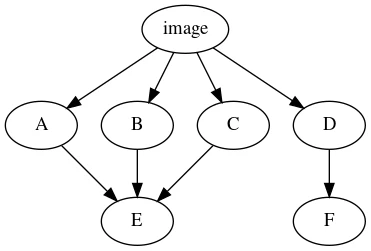
In this example, counting the total number of references to each node in the graph yields the following result:
| pkg | refs |
|---|---|
| E | 3 |
| D | 2 |
| F | 2 |
| A,B,C | 1 |
Assuming we are constrained to 4 layers, the current algorithm would yield these layers:
L1: E L2: D L3: F L4: A, B, C
The initial proposal for this design is that additional data should be considered in addition to the total number of references, in particular a distinction should be made between direct and indirect references. Packages that are only referenced indirectly should be merged with their parents.
This yields the following table:
| pkg | direct | indirect |
|---|---|---|
| E | 3 | 3 |
| D | 2 | 2 |
| F | 1 | 2 |
| A,B,C | 1 | 1 |
Despite having two indirect references, F is in fact only being referred to once. Assuming that we have no other data available outside of this graph, we have no reason to assume that F has any popularity outside of the scope of D. This might yield the following layers:
L1: E L2: D, F L3: A L4: B, C
D and F were grouped, while the top-level references (i.e. the packages explicitly requested by the user) were split up.
An assumption is introduced here to justify this split: The top-level packages is what the user is modifying directly, and those groupings are likely unpredictable. Thus it is opportune to not group top-level packages in the same layer.
This raises a new question: Can we make better decisions about where to split the top-level?
(Even closer to) ideal layering using (even) more data
So far when deciding layer layouts, only information immediately available in the build graph of the image has been considered. We do however have much more information available, as we have both the entire nixpkgs-tree and potentially other information (such as download statistics).
We can calculate the total number of references to any derivation in nixpkgs and use that to rank the popularity of each package. Packages within some percentile can then be singled out as good candidates for a separate layer.
When faced with a splitting decision such as in the last section, this data can
aid the decision. Assume for example that package B in the above is actually
openssl, which is a very popular package. Taking this into account would
instead yield the following layers:
L1: E, L2: D, F L3: B, L4: A, C
Layer budgets and download size considerations
As described in the introduction, there is a finite amount of layers available for each image (the “layer budget”). When calculating the layer distribution, we might end up with the “ideal” list of layers that we would like to create. Using our previous example:
L1: E, L2: D, F L3: A L4: B L5: C
If we only have a layer budget of 4 available, something needs to be merged into the same layer. To make a decision here we could consider only the package popularity, but there is in fact another piece of information that has not come up yet: The actual size of the package.
Presumably a user would not mind downloading a library that is a few kilobytes in size repeatedly, but they would if it was a 200 megabyte binary instead.
Conversely if a large binary was successfully cached, but an extremely popular small library is not, the total download size might also grow to irritating levels.
To avoid this we can calculate a merge rating:
merge_rating(pkg) = popularity_percentile(pkg) × size(pkg.subtree)
Packages with a low merge rating would be merged together before packages with higher merge ratings.
Implementation
There are two primary components of the implementation:
-
The layering component which, given an image specification, decides the image layers.
-
The popularity component which, given the entire nixpkgs-tree, calculates the popularity of packages.
Layering component
It turns out that graph theory’s concept of dominator trees maps reasonably well onto the proposed idea of separating direct and indirect dependencies. This becomes visible when creating the dominator tree of a simple example:
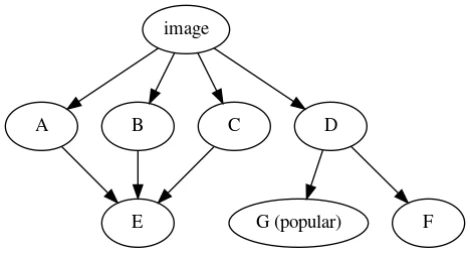
Before calculating the dominator tree, we inspect each node and insert extra edges from the root for packages that match a certain popularity or size threshold. In this example, G is popular and an extra edge is inserted:
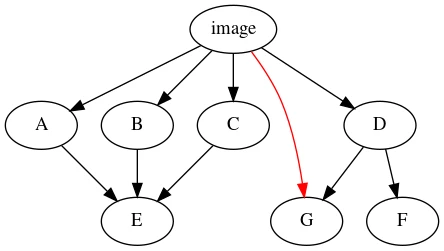
Calculating the dominator tree of this graph now yields our ideal layer distribution:
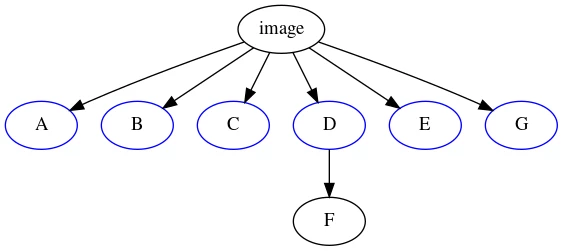
The nodes immediately dominated by the root node can now be “harvested” as image layers, and merging can be performed as described above until the result fits into the layer budget.
To implement this, the layering component uses the gonum/graph library which
supports calculating dominator trees. The program is fed with Nix’s
exportReferencesGraph (which contains the runtime dependency graph and runtime
closure size) as well as the popularity data and layer budget. It returns a list
of layers, each specifying the paths it should contain.
Nix invokes this program and uses the output to create a derivation for each layer, which is then built and returned to Nixery as usual.
TIP: This is implemented in layers.go in Nixery. The file starts
with an explanatory comment that talks through the process in detail.
Popularity component
The primary issue in calculating the popularity of each package in the tree is that we are interested in the runtime dependencies of a derivation, not its build dependencies.
To access information about the runtime dependency, the derivation actually needs to be built by Nix - it can not be inferred because Nix does not know which store paths will still be referenced by the build output.
However for packages that are cached in the NixOS cache, we can simply inspect
the narinfo-files and use those to determine popularity.
Not every package in nixpkgs is cached, but we can expect all popular packages to be cached. Relying on the cache should therefore be reasonable and avoids us having to rebuild/download all packages.
The implementation will read the narinfo for each store path in the cache at a
given commit and create a JSON-file containing the total reference count per
package.
For the public Nixery instance, these popularity files will be distributed via a GCS bucket.
TIP: This is implemented in popcount in Nixery.
Hopefully this detailed design review was useful to you. You can also watch my NixCon talk about Nixery for a review of some of this, and some demos.